![[베이징=AP/뉴시스] 중국 인공지능(AI) 스타트업 딥시크가 자사의 생성형 AI 모델 ‘R1’의 업그레이드 버전을 조용히 공개했다. 업계는 미국 최고 수준의 모델들과의 격차를 빠르게 좁히고 있는 점에 주목하고 있다. 딥시크 앱 로고. 2025.05.30 /사진=뉴시스](https://image.fnnews.com/resource/media/image/2025/05/30/202505301731559454_l.jpg)
[파이낸셜뉴스] 중국 인공지능(AI) 딥시크의 최신 추론 모델 'R1-0528'이 구글의 '제미나이' 데이터를 무단 활용했다는 의혹이 제기되고 있다. 전문가들은 딥시크의 추론 과정 등을 토대로 딥시크가 선두업체 데이터를 일부 활용했을 것으로 추정한다. 딥시크는 지난해부터 올초까지 자신을 '챗GPT'라고 언급하기도 한 바 있다.
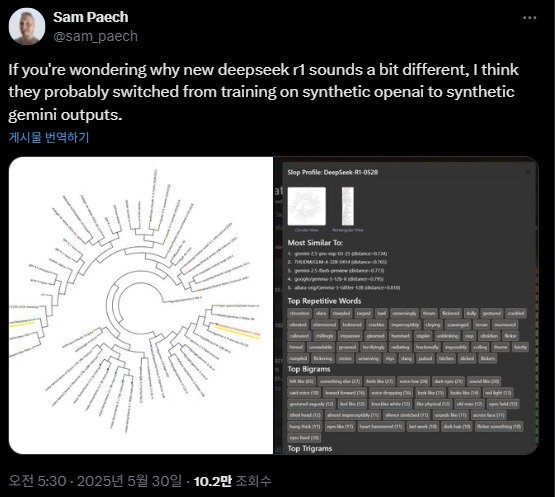
"제미나이 2.5 프로랑 말투가 비슷한데?"
9일 테크크런치 등 주요 외신에 따르면 호주 멜버른의 AI 개발자 샘 페이크는 자신의 X(옛 트위터)에 딥시크의 R1-0528 모델이 구글 제미나이 2.5 프로와 유사한 어휘를 선호한다는 분석 결과를 공개했다.
페이크는 "딥시크가 챗GPT에서 제미나이 기반 합성 데이터를 활용하기로 한 것으로 보인다"고 언급했다.
딥시크의 데이터 무단 사용 의혹은 이번이 두 번째다. 딥시크의 V3 모델이 자신을 '챗GPT'라고 언급하는 현상이 지난해 12월부터 올해초까지 빈번하게 발생하면서 딥시크가 오픈AI 채팅 로그를 훈련 데이터로 사용했다는 의혹이 제기됐다.
MS, "오픈AI데이터, 누군가 대규모 추출해 증류에 활용"
후발업체가 선두업체의 AI 데이터를 활용하는 일은 업계 관행이 되어가고 있다. 문제는 이런 데이터 재활용을 어느 선까지 불법 행위로 볼 수 있느냐다. 타사 데이터를 뽑아내 소형 언어모델에 쓰는 '증류' 작업은 생성형 AI 업계에선 빈번하게 발생하고 있다.
마이크로소프트(MS) 보안팀도 최근 오픈AI API로 만든 데이터를 '증류'에 활용하기 위해 일부 개발자들이 대규모로 추출한 정황을 포착했다고 발표한 바 있다. MS는 해당 개발자들이 딥시크와 연관이 있을 것으로 봤다. 다만 전문가들은 증류 기법 자체는 업계 관행으로 보고 있다. 이 때문에 증류를 소송까지 가는 경우는 극히 드문 것으로 다만 증류 기법 자체는 업계의 관행인 점 등을 고려해 소송까지 이어지진 않은 것으로 전해진다. 현재 MS·오픈AI·구글 등 빅테크들은 데이터 무단 수집·활용을 막는 조치를 강화하고 있다.
ksh@fnnews.com 김성환 기자
※ 저작권자 ⓒ 파이낸셜뉴스, 무단전재-재배포 금지