(서울=뉴스1) 김정현 기자 = 카카오가 한국어와 한국 문화를 가장 잘 이해하는 고도화된 멀티모달 인공지능(AI) 기술 연구 성과를 발표했다. 벤치마크 평가 결과, 영어 음성 성능에서 GPT-4o와 유사한 수준을, 한국어 음성 인식 및 합성, 감정 인식 능력에서는 월등히 높은 수준을 기록했다.
카카오는 12일 테크블로그를 통해 한국적 맥락 이해에 최적화된 통합 멀티모달 언어모델 '카나나-o(Kanana-o)와 멀티모달 임베딩(Embedding) 모델 '카나나-v-임베딩'(Kanana-v-embedding)의 개발 과정과 성능을 공개했다.
카나나-o는 텍스트와 음성, 이미지를 동시에 이해하고 실시간으로 답변하는 통합 멀티모달 언어모델이다. 글로벌 모델 대비 한국어 맥락 이해에서 높은 성능을 보유하고, 사람처럼 자연스럽고 풍부한 표현력을 갖추고 있는 것이 특징이다.
카카오는 카나나-o의 지시이행 능력을 고도화해 사용자의 숨은 의도와 복잡한 요구사항까지 파악할 수 있도록 개선했다.
자체 구축한 데이터셋으로 학습을 진행했다. 이로써 다양한 모달리티의 입출력에 대해서도 기존 언어모델의 성능을 유지하고, 단순 질의응답을 넘어 △요약 △감정 및 의도 해석 △오류 수정 △형식 변환 △번역 등 다양한 과업을 수행할 수 있도록 성능을 끌어올렸다.
또 고품질 음성 데이터와 직접 선호 최적화(DPO) 기술을 적용해 억양·감정·호흡 등을 정교하게 학습시켰다. 기쁨·슬픔·분노·공포 등 상황 별 생생한 감정은 물론 미세한 음색·어조 변화 등에 따른 감정 표현 능력까지 향상했다.
호스트와 게스트가 대화를 주고받는 팟캐스트 형태의 데이터셋을 구축해, 끊김없이 자연스럽게 이어지는 멀티턴(Multi-turn) 대화도 가능해졌다.
카카오는 향후 더욱 자연스러운 동시 대화(Full-duplex)와 상황에 맞는 사운드스케이프(Soundscape)를 실시간 생성할 수 있는 진화된 모델로 발전시킬 예정이다.
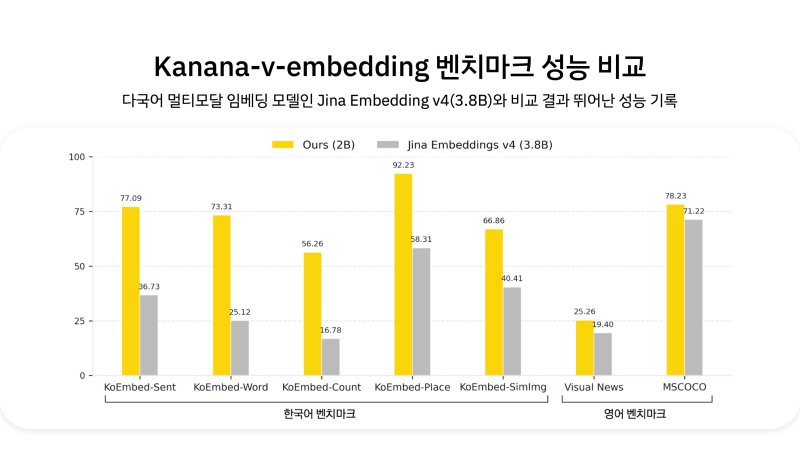
함께 공개된 카나나-v-embedding은 텍스트와 이미지를 동시에 이해해 처리할 수 있는 한국형 멀티모달 모델이다. 텍스트로 이미지를 검색하거나, 사용자가 선택한 이미지와 관련된 정보를 검색하고, 이미지가 포함된 문서 검색 등을 지원한다.
이 모델은 실제 서비스 적용을 목표로 개발되어 한국어와 한국 문화에 대한 이해도가 탁월하다. 경복궁, 붕어빵 같은 고유명사는 물론, 오타가 포함된 단어도 문맥을 파악해 정확한 이미지를 찾아준다. 또 '한복 입고 찍은 단체 사진'처럼 복합적인 조건도 정확히 이해해, 조건의 일부에만 해당하는 사진을 걸러낼 수 있는 높은 변별력을 갖췄다.
현재 카카오는 카나나-v-embedding를 내부에서 광고 소재의 유사도를 분석 및 심사하는 시스템에 적용 중이다. 향후 비디오나 음성으로 범위를 확대해 더욱 다양한 서비스에도 적용할 계획이다.
김병학 카카오 카나나 성과리더는 "실제 서비스 환경을 통해 사용자들의 일상 속 AI 기술 경험을 만들어 나가고, 사람처럼 상호작용 할 수 있는 AI의 구현에 주력해 갈 것"이라고 말했다.
한편 카카오는 모바일 기기 등 온디바이스 환경에서 동작할 수 있는 멀티모달 모델의 경량화 연구를 진행 중이다. 이와 더불어 MoE(Mixture of Experts) 구조를 적용한 고성능, 고효율 모델인 '카나나-2' 개발을 준비하고 있다.
※ 저작권자 ⓒ 뉴스1코리아, 무단전재-재배포 금지